PostgreSQL 9.0 createdb Revelations (Updated)
2011-08-27 15:18:16 by jdixon
One of my first projects at Heroku has been to modernize our shared PostgreSQL offering (working with @asenchi). As we get closer to internal testing of our new service, @markimbriaco asked for benchmarks looking for any bottlenecks in PostgreSQL 9.x when creating large quantities of small databases. We've seen instances where Pg 8.3 will start to choke after 2000 databases on the same server and we're hoping that 9.x alleviates this issue.
My initial test was overly simplistic but still revealed some interesting patterns. I started with createdb on the command-line, generating 8000 roles and empty databases, serially. The results were promising, with PostgreSQL 9.0.4 (Ubuntu 10.04) able to scale up without any noticeably increasing latency. Unfortunately, it's not a terribly useful benchmark given the absence of any workload. And yet, I couldn't help but notice a pattern in the scatter plot:

Notice the gap between 500 and 600 ms? I don't have an explanation for this but I suspected that Pg has an internal condition that triggers for actions that take 500ms or longer. Regardless, our primary expectations had been met. Whatever bottleneck 8.3 demonstrated when creating databases on a server with large quantities of existing small databases appears to be fixed in 9.0.
The next test was to run a similar sequence with our new application server. It offers an internal RESTful API using Sinatra and Sequel to provision and manage customer databases on shared servers. The results for this run were even more enlightening. Check out the stratification:
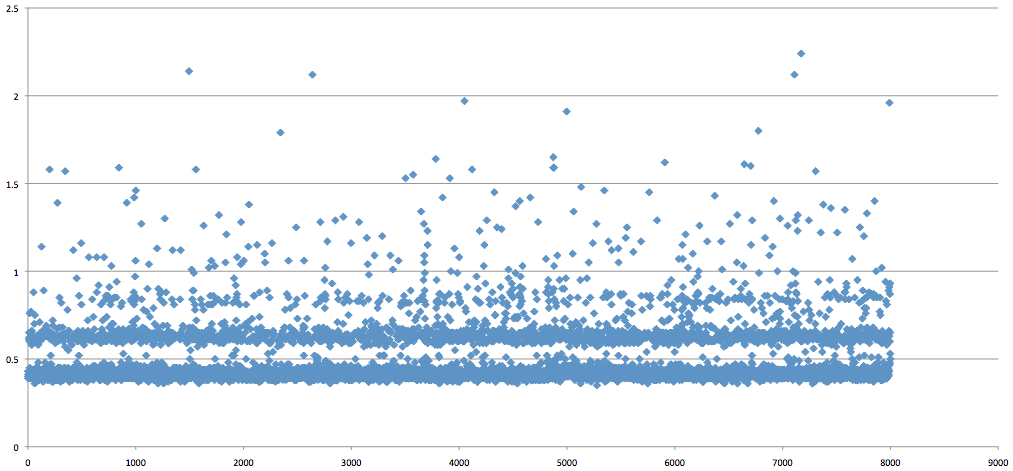
Not only is the initial gap (around 400ms) even more pronounced, but you can see a pattern of latency introduced at 200ms intervals after the initial 400ms delay. I have no explanation for this, but I wanted to publish these results and see if anyone else has a guess as to what might be causing these patterns.
UPDATE: To rule out any distortion caused by GNU time, I ran another test using Ruby's Time class to get a more accurate representation. In the most simple terms, we start the clock with Time.now, connect to the database (no caching), create a role, create the database and stop the clock. Output is logged and then imported into Excel for plotting. I think the results speak for themselves (measured in milliseconds):

Add a comment:

 RSS 1.0
RSS 1.0
Comments
at 2011-08-28 10:15:11, Jeff Blaine wrote in to say...
Wild idea off the top of my head. Nothing you don't already know...
Do 1000 with strace -f -c -o strace$i.log
They shouldn't differ, but will. Where? Why? Leave off -c, perhaps sort the new strace logs by system call, then diff some of them?