Graphite Tip - A Better Way to Store Events
2014-01-05 20:54:03 by jdixon
Graphite is well known for storing simple key/value metrics using the Whisper time-series database on-disk format. What is not well known about Graphite is that it also ships with a feature known as Events that supports a richer form of metrics storage suitable for, well, events. Imagine a place where you could store tagged metrics and additional data relevant to the event (e.g. code snippets, comments, etc). Many folks use NoSQL databases such as HBase for this purpose, and that's a perfectly reasonable approach. However, if you'd like to store these somewhere where they can be correlated with the rest of your Graphite metrics, then Events might be a good fit for you.
- Comments (11)
Migrating Graphite from SQLite to PostgreSQL
2013-12-14 19:29:20 by jdixon
As mentioned in my previous article, I no longer recommend using SQLite as a Graphite backend for anything outside of development or testing work. It is too lenient with data types, and doesn't provide the levels of concurrency I'd like to see in an RDBMS for a production web service.
This opinion was cultivated almost exclusively from my recent experience migrating a single-node Graphite instance with an SQLite database to an HA pair of Graphite nodes with a shared PostgreSQL backend. For those of you considering migrating off SQLite to PostgreSQL, this article documents my initial struggles and eventual fixes for this transition.
- Comments (4)
Why You Shouldn't use SQLite with Graphite
2013-12-10 19:44:07 by jdixon
If you've ever had the pleasure of installing Graphite, you're almost certainly aware that it uses Django as it's web framework. In order to support features like saving graphs and dashboards, Graphite needs somewhere to store the data that describes these objects. As you might expect, a relational database with support for SQL is a dandy place for this sort of relational data. Django supports a number of RDBMS backends using the Django ORM, making it relatively painless to get started with Graphite in a development or test environment using the popular SQLite database engine.
- Comments (0)
Sequel Migrations on Heroku
2011-11-30 10:39:02 by jdixon
I find myself using Sequel in conjunction with Sinatra these days to write more of my web applications. Never having been a fan of ORMs in general, and mostly comfortable with the ickier bits of SQL wizardry, it took me a while to warm up to the idea of using one for database migrations. But I've seen the possibilities with stuff like ActiveRecord. Being able to migrate my schema into a versioned state is "dee-lish".
- Comments (0)
PostgreSQL 9.0 createdb Revelations (Updated)
2011-08-27 15:18:16 by jdixon
One of my first projects at Heroku has been to modernize our shared PostgreSQL offering (working with @asenchi). As we get closer to internal testing of our new service, @markimbriaco asked for benchmarks looking for any bottlenecks in PostgreSQL 9.x when creating large quantities of small databases. We've seen instances where Pg 8.3 will start to choke after 2000 databases on the same server and we're hoping that 9.x alleviates this issue.
My initial test was overly simplistic but still revealed some interesting patterns. I started with createdb on the command-line, generating 8000 roles and empty databases, serially. The results were promising, with PostgreSQL 9.0.4 (Ubuntu 10.04) able to scale up without any noticeably increasing latency. Unfortunately, it's not a terribly useful benchmark given the absence of any workload. And yet, I couldn't help but notice a pattern in the scatter plot:

Notice the gap between 500 and 600 ms? I don't have an explanation for this but I suspected that Pg has an internal condition that triggers for actions that take 500ms or longer. Regardless, our primary expectations had been met. Whatever bottleneck 8.3 demonstrated when creating databases on a server with large quantities of existing small databases appears to be fixed in 9.0.
The next test was to run a similar sequence with our new application server. It offers an internal RESTful API using Sinatra and Sequel to provision and manage customer databases on shared servers. The results for this run were even more enlightening. Check out the stratification:
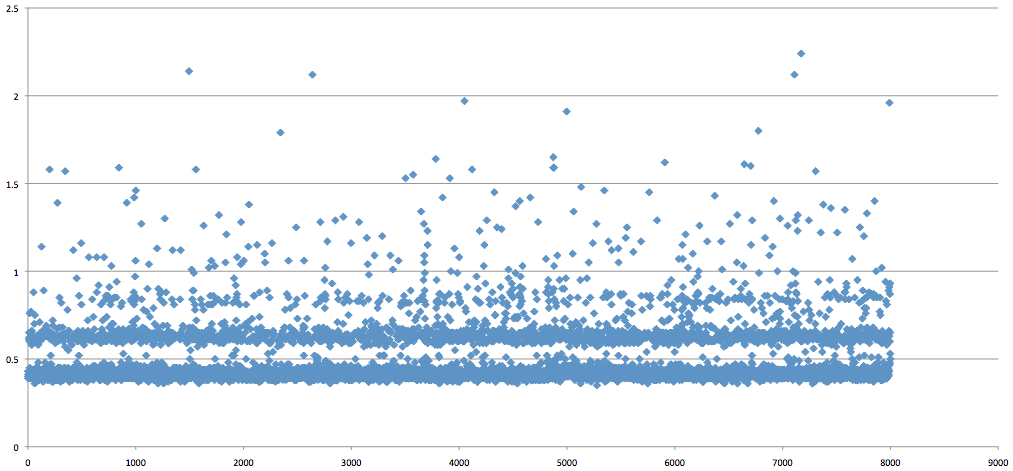
Not only is the initial gap (around 400ms) even more pronounced, but you can see a pattern of latency introduced at 200ms intervals after the initial 400ms delay. I have no explanation for this, but I wanted to publish these results and see if anyone else has a guess as to what might be causing these patterns.
UPDATE: To rule out any distortion caused by GNU time, I ran another test using Ruby's Time class to get a more accurate representation. In the most simple terms, we start the clock with Time.now, connect to the database (no caching), create a role, create the database and stop the clock. Output is logged and then imported into Excel for plotting. I think the results speak for themselves (measured in milliseconds):

- Comments (1)
Achievement Unlocked: Heroku Operations
2011-07-11 11:59:56 by jdixon

I'm proud to announce that I'll be starting at Heroku in a couple of weeks. This is an exciting opportunity to work at a place that breathes DevOps and eats Infrastructure as Code. Whenever you hear someone describing "Platform as a Service", there's a good chance that Heroku will be the example they're talking about.
I first met Mark Imbriaco (@markimbriaco) when he was the Operations Manager at 37signals. Mark's a level-headed guy with a undeniable talent for Web Operations and an excellent track record for supporting his customers. It was no surprise to me when he took over as the Director of Cloud Operations at Heroku. Even after the acquisition by Salesforce.com last December, they've continued to innovate at a breakneck speed (proof here, here, here and here).
Heroku development and operations teams get to work on the sort of rapid scaling and engineering challenges that pique my interest. I'm doubly excited to be able to share the fact that I'll be joining up simultaneously with Curt Micol (@asenchi) as the newest Operations Engineers on Mark's team. It's an odd coincidence that we're both big fans of BSD. Hopefully nobody holds that against us. ;-).
Needless to say I'm thrilled about the whole thing and hope that it gives me more cool stuff to write about here. Stay tuned.
- Comments (2)

 RSS 1.0
RSS 1.0