Migrating Graphite from SQLite to PostgreSQL
2013-12-14 19:29:20 by jdixon
As mentioned in my previous article, I no longer recommend using SQLite as a Graphite backend for anything outside of development or testing work. It is too lenient with data types, and doesn't provide the levels of concurrency I'd like to see in an RDBMS for a production web service.
This opinion was cultivated almost exclusively from my recent experience migrating a single-node Graphite instance with an SQLite database to an HA pair of Graphite nodes with a shared PostgreSQL backend. For those of you considering migrating off SQLite to PostgreSQL, this article documents my initial struggles and eventual fixes for this transition.
- Comments (4)
Surge 2012 Postmortem
2012-09-28 18:35:11 by jdixon
The curtain has lowered on another couple days of scalability lessons and "disaster porn" at this year's Surge conference. Despite my initial misgivings that the registration fees were too high, the conference organizers have once again put together an experience that is quite possibly the best among all technically-oriented events.
- Comments (0)
#monitoringsucks BoF at Surge 2012
2012-09-27 14:13:16 by jdixon
Kicking off this year's Surge conference was a pair of BoF sessions. The #monitoringsucks one was packed, to the extent that a number of us had to steal chairs from the Chef BoF across the hall. I remembered to write down some of the highlights from the session. Note that I'm not quoting anyone directly and am summarizing each speaker to the best of my recollection. If you were at the event and remember things differently, please notify me in the comments section below.
- Comments (0)
Graph Porn and Sharing
2012-07-01 13:43:14 by jdixon
Part of what I see myself doing (by writing blog posts, creating software like Tasseo, etc) is to try and help others learn better ways of communicating our operational knowledge through visualization tools and methodologies. While I've gotten a lot of positive feedback from my Graphite articles, what I haven't seen as much is a two-way sharing of the harvested data made possible through these experiences.
I think there are a couple possible reasons for this: first, we work with "propietary" data that our employers might not want divulged; second, we assume our data is immaterial and not worth sharing. For the former, I think this is a very similar argument that many of us had with employers during the push to open source software. There is much to be gained by sharing our raw data (perhaps without all of the proprietary metadata and labels that make it relevant to our business) and seeing those examples improved upon and returned by our peers.
- Comments (0)
Thoughts on Surge 2011
2011-09-30 22:03:47 by jdixon
I had another great year at the Surge scalability conference in Baltimore, MD. Many of you know that I consider Surge to be "my baby", having conceived of the original conference vision, name and motto while employed at OmniTI. Even though I've moved on, I'm proud to see it grow and flourish while keeping its intimate feel intact.
Long story short, Surge 2011 kicked ass and took names. The speaker lineup was impressive and there were improvements across the board. Audio and video were outsourced to a professional team. On Thursday, lunch was provided and after the last session, Google had a nice party with plenty of hors d'oevers and beer. Everyone appeared to have a great time, sharing war stories and networking with peers.
I was invited by this year's team to organize the Lightning Talks on Wednesday night. Although I wish I'd scrapped the Karaoke PowerPoint event as I was inclined to do, the rest of the night went off without a hitch. The talks were consistently awesome, with Adam Jacob putting the capper on the evening.
Sessions on Thursday were excellent. Ben Fried held keynote honors, describing one of his greatest failures and how it helped shape the way Google IT operates. Artur Bergman was typically irreverent towards Linux kernel developers and inferior hardware. My favorite talk of the conference happened to come from Mark Imbriaco, the Director of Cloud Operations at Heroku (and coincidentally, my boss). But seriously, it was a brilliant interactive session full of insightful real-life incident response tactics and Q&A with the audience. Ironically, our Heroku operations team had to skip the 2:30pm slot to respond to an urgent incident within our architecture. My day wrapped up with a hilarious Choose-Your-Own-Adventure talk by Adam Jacob of Opscode.
Friday's sessions were good but struggled to compete with the consistently high quality of the previous day. I enjoyed Theo Schlossnagle's dissection of the Circonus real-time data subsystems, even though I'm intimately familiar with them already (as former Product Manager of the same). I caught the latter portions of Baron Schwartz's talk on performance metrics and the first half of Mike Panchenko's talk on cloud infrastructure. Unfortunately I had to skip the latter half of the conference's last day due to family commitments, but I've heard great things on Twitter about the remaining sessions.
My only real complaint was the Internet connectivity. Unlike last year, where I insisted on using Port Networks exclusively, this year the organizers chose to outsource part of the conference network to the Tremont IT staff. I'm unsure of the specific cause of the failures, but the symptoms were random failures to load TCP connections from various sites. On the first day, for example, I was unable to load the Surge website without it blocking on the Fontdeck CDN. The next day, I couldn't SSH to any EC2 hosts (although I was able to get to my personal server at ARP Networks) or load Basho and Etsy websites. Everyone I spoke with encountered similar failures, but not always the same sites (ruling out DNS issues). It appeared to be caused by overzealous application filtering or possibly a connection limit. I spoke to multiple OmniTI employees and nobody knew what the cause was, other than it had something to do with the Tremont service.
Also, I noticed a distinct lack of war stories as compared to last year's event. Surge was envisioned as a place where internet practitioners could share and learn from each other's mistakes. With a couple distinct exceptions, it just wasn't the case this year. It felt more like a chapter from O'Reilly Strata 2011 (read: Big Data) than Surge 2010. Nevertheless, there was plenty of good information to be gleaned throughout.
I had an incredible time at this year's event with my old friends at OmniTI, my operations and engineering compadres at Heroku, and countless friends and associates from IRC, Twitter and real life. As much as I enjoy conferences like Velocity, OSCON and DevOpsDays, I don't think they hold a candle to the concentration of operational and engineering excellence that you find at Surge. I'm thrilled that they're committed to keeping Surge at the Tremont. Although it's a quirky building with limited modernities, it guarantees that this event will never grow too large or become "commercially compromised". Hope to see all of you (well, 350 of you anyways) again next year.
- Comments (0)
PostgreSQL 9.0 createdb Revelations (Updated)
2011-08-27 15:18:16 by jdixon
One of my first projects at Heroku has been to modernize our shared PostgreSQL offering (working with @asenchi). As we get closer to internal testing of our new service, @markimbriaco asked for benchmarks looking for any bottlenecks in PostgreSQL 9.x when creating large quantities of small databases. We've seen instances where Pg 8.3 will start to choke after 2000 databases on the same server and we're hoping that 9.x alleviates this issue.
My initial test was overly simplistic but still revealed some interesting patterns. I started with createdb on the command-line, generating 8000 roles and empty databases, serially. The results were promising, with PostgreSQL 9.0.4 (Ubuntu 10.04) able to scale up without any noticeably increasing latency. Unfortunately, it's not a terribly useful benchmark given the absence of any workload. And yet, I couldn't help but notice a pattern in the scatter plot:

Notice the gap between 500 and 600 ms? I don't have an explanation for this but I suspected that Pg has an internal condition that triggers for actions that take 500ms or longer. Regardless, our primary expectations had been met. Whatever bottleneck 8.3 demonstrated when creating databases on a server with large quantities of existing small databases appears to be fixed in 9.0.
The next test was to run a similar sequence with our new application server. It offers an internal RESTful API using Sinatra and Sequel to provision and manage customer databases on shared servers. The results for this run were even more enlightening. Check out the stratification:
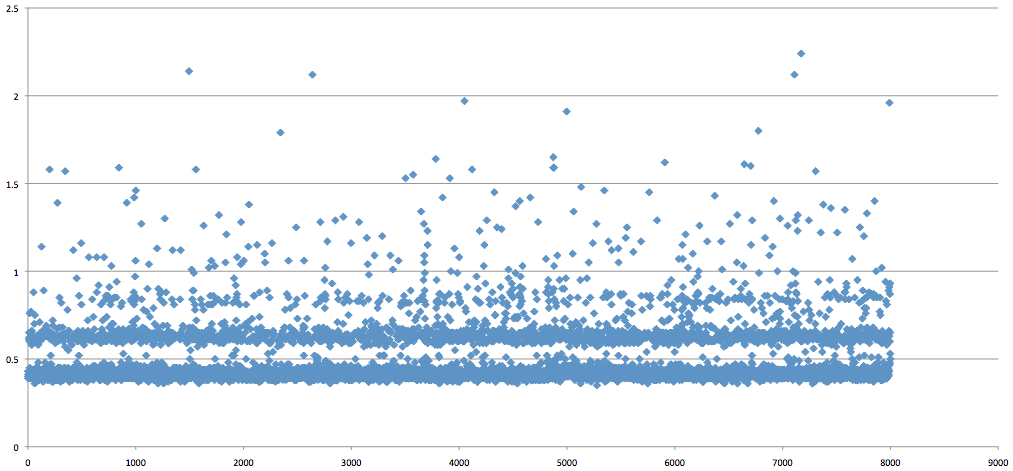
Not only is the initial gap (around 400ms) even more pronounced, but you can see a pattern of latency introduced at 200ms intervals after the initial 400ms delay. I have no explanation for this, but I wanted to publish these results and see if anyone else has a guess as to what might be causing these patterns.
UPDATE: To rule out any distortion caused by GNU time, I ran another test using Ruby's Time class to get a more accurate representation. In the most simple terms, we start the clock with Time.now, connect to the database (no caching), create a role, create the database and stop the clock. Output is logged and then imported into Excel for plotting. I think the results speak for themselves (measured in milliseconds):

- Comments (1)
Your Mom is Crazy
2009-08-24 11:37:37 by jdixon
When people ask you what you do for a living, do you answer "geek"? While shopping for a new car, is your primary criteria "good, fast, cheap... pick two"? Did you get goosebumps the first time you played with VMware's virtual switching/VLAN support? If so, you might be a perfect fit for our team.
OmniTI is looking for someone with real UNIX chops. We have a passion for what we do and it shows. A typical day in the Ops team is a heaping pile of scalability, smothered with resiliency, and a smattering of optimization. We eat and drink Open Source. We poop cold steel. You will be tempered, and you'll love every minute of it. If this sounds like your sort of thing, shoot me a line so we can talk.
P.S. We're the place your mom warned you about.
- Comments (0)
Noit Grows Hair on Your Chest
2009-08-15 14:09:13 by jdixon
Todd Hoff over at High Scalability takes a look at Reconnoiter. He went through the [currently] arduous task of installing and configuring it manually; setting up checks can be a hairy experience. But the end result seems to justify the initial pain. It's a very exciting (and useful) application that will only get better as the #noit devs continue to hack on it.
As an Ops guy over at OmniTI, I've been fortunate to watch Reconnoiter's incubation process. Theo Schlossnagle is probably one of the smartest guys in this industry and he gets scalability issues. We've batted around ideas about network trend and analysis tools before (e.g. NFDB) so naturally I'm anxious to see where Noit takes us.
- Comments (0)

 RSS 1.0
RSS 1.0