Graphite Tip - A Better Way to Store Events
2014-01-05 20:54:03 by jdixon
Graphite is well known for storing simple key/value metrics using the Whisper time-series database on-disk format. What is not well known about Graphite is that it also ships with a feature known as Events that supports a richer form of metrics storage suitable for, well, events. Imagine a place where you could store tagged metrics and additional data relevant to the event (e.g. code snippets, comments, etc). Many folks use NoSQL databases such as HBase for this purpose, and that's a perfectly reasonable approach. However, if you'd like to store these somewhere where they can be correlated with the rest of your Graphite metrics, then Events might be a good fit for you.
- Comments (11)
My Impressions of InfluxDB
2013-11-11 12:15:38 by jdixon
I mentioned last week that I was planning to look closer at InfluxDB this past weekend, and some folks asked me to do a writeup on my findings.
InfluxDB is a time-series metrics and events database based on the LevelDB key-value store. LevelDB was written and open sourced by Google, and is an optional backend for Riak. InfluxDB (or "Influx", for short) inherits many of LevelDB's default characteristics, which means it's optimized for writes and uses compression by default, but it can be slow for reads and deletes.
- Comments (9)
What's Up with Playfair?
2013-10-19 02:58:37 by jdixon
Within the last hour I stumbled across a tweet from Dan Ryan mentioning a new hosted Graphite + StatsD service called Playfair. As you might expect, this piqued my interest.
Immediately, I thought of Hosted Graphite and wondered how this compares with their offering. Would it have its own dashboard? Was it a DigitalOcean-backed Graphite instance (admittedly, something I've considered trying to package up myself)? I hopped over to their website and looked around.
- Comments (1)
Graphite Tip - Mixing Lines and Stacks
2013-08-16 13:43:15 by jdixon
One of Graphite's shortcomings is that it's not easy to construct a composite chart of both lines and area sections. In fact, it's not possible at all unless you're willing to stack your areas. But if you are dealing with data where it makes sense to stack them, and you want to correlate that with something else as a line series, here's an example demonstrating how you can do it.
- Comments (1)
Are We Ready to Kill Thresholds?
2013-06-26 09:12:54 by jdixon
I've been hearing a lot of chatter from various sources that adaptive fault detection is going to be The New Shit ™ and that static thresholds are virtually useless because they lack context. While I agree that some of the more advanced techniques sound amazing (and make no mistake, I'm really excited about the possibilities here), it's foolish to think that thresholds as a measure of fault conditions are useless.
- Comments (3)
Dusk - Yet Another Graphite Dashboard
2013-06-21 19:36:28 by jdixon
Not too long ago we were looking for a way to visualize a group of metrics across our entire fleet. Although you could render all of the metrics on one graph, it becomes nearly impossible to distinguish one from another. Jesse Newland (@jnewland) suggested that we look at Cubism.js' horizon charts. The nice thing about horizon charts is that you can cram a lot of information into a small vertical space, due to the way they render "overlapping" values with increasing intensity. One thing led to another, and soon Dusk was born.
- Comments (6)
Call for OSS Project Instrumentation
2013-05-28 09:56:28 by jdixon
As an open source developer, some portion of my time is spent not just coding and responding to user feedback, but to act as a Project-slash-Product Manager. I have to determine which bugs to prioritize, which features are necessary, and where to allocate my finite resources. Much of this is driven by what interests me at the time and which features will best fit into my overarching vision for the project.
- Comments (2)
Graphite Tip - Counting Number of Metrics Reported
2013-05-27 13:59:50 by jdixon
There's been many a time when I've asked the question "I wonder how many hosts are sending this metric?" Unfortunately there's no built-in Graphite function for determining the number of hosts submitting a particular metric (or tree of metrics). But this morning I stumbled across a brilliant hack of a Graphite query by Jesse Newland (@jnewland) for rendering this value.
- Comments (7)
WTF is Chartroulette
2013-05-13 16:32:42 by jdixon
Sometimes the silliest features are the ones that inspire you most. This was certainly the case with the new Chartroulette view that I recently merged into Descartes. Because I wanted so badly for this to become a reality it forced me to knock out some other dependencies (user model, favorite dashboards, and better user mapping) rather quickly.
To be fair, there's nothing silly about the idea behind Chartroulette. At GitHub we have an internal app by @maddox that allows users to rotate any Mac or iOS-based device's screen through a series of website URLs. Typically we use this to cycle through dashboards or graphs. While I'd love to see this open-sourced, I know that Jon is a very busy guy so I figured that emulating this functionality within Descartes might be the next best thing.
- Comments (0)
Feeding Params into Descartes
2013-05-06 13:07:32 by jdixon
This is a relatively minor enhancement in terms of LoC but it would take too many words to describe on Twitter so here we are. Recent commits added support for passing interval and columns parameters into Descartes views (graphs, dashboards, etc). Previously you would always get the default layout whenever loading any Descartes page.
- Comments (0)
Graphite Tip - Group by Node
2013-04-14 18:23:29 by jdixon
In the process of setting up some graphs for Status Board, I thought it would be nice to render my GitHub activity (in terms of commits). As I demonstrated in a post last year, you can fire off a metric to Graphite using GitHub's post-commit webhook feature. Rendered with drawAsInfinite, this is nice for getting a rough visualization of your commit activity, but doesn't provide total counts. Alternatively, you could use group with summarize to get totals per interval, but you wouldn't be able to view per-repository numbers.
- Comments (0)
Contribute to Open Source Monitoring Projects
2013-04-03 16:40:34 by jdixon
You say you want to contribute to an Open Source project, but you're not sure where to start? Have an interest in monitoring, trending or logging software? Hop on over to the Monitorama Hackathon issues list and take a look around. In the weeks leading up to the event we seeded the repo with a bunch of tasks/feature requests/bug reports that are easily digestible over the course of a day or two. These are a great place to get started on a new project, or nail out some quick issues that have an immediate impact.
- Comments (0)
Graphite Tip - Grouping Release Metrics in the Legend
2013-04-03 12:48:07 by jdixon
Last year I gave examples for using drawAsInfinite to help visualize the frequency of particular events (deploys, commits, etc). One of the side effects that I failed to mention is that these will quickly fill up your legend with labels, making it impossible to view the legend at all. It's likely that you've seen this sort of thing at least once (assuming you forced hideLegend=false):

- Comments (0)
Graphite Tip - Converting Zeroes into Nulls
2013-04-01 17:43:26 by jdixon
I was looking at some internal data for @jnunemaker and @jfryman today when I stumbled across the Data Filters group of functions inside the Graphite composer. These functions are handy for those times when you want to exclude a subset of a particular series of data, for whatever reason. In our case, we were looking at some metrics where we had spikes of data that were interesting, and a lot of uninteresting data reported as zeroes.
- Comments (0)
Thoughts from Monitorama 2013
2013-03-30 10:34:42 by jdixon
This is not your typical conference review. This is a braindump of my thoughts following the organization and execution of the 2013 Monitorama Conference and Hackathon in Boston (Cambridge), Massachusetts.
- Comments (7)
Monitorama Hackathon
2013-03-05 10:38:23 by jdixon
One of the overarching themes that drove me to organize Monitorama was the desire to bring together OSS developers in an effort to improve the current state of monitoring and trending software. I grew impatient with the lack of measurable progress that happens at the typical SysAdmin/WebOps/DevOps-style events, which tend to focus on automation and traditional operations fare. While I'm pleased that everyone is excited about our speaker lineup, the works we accomplish at this Hackathon will be the true barometer of our success. With this in mind I have some points to consider as you prepare for your attendance and participation at the event.
- Comments (1)
Assembling Uptime, Umpire and Graphite
2012-10-16 11:05:08 by jdixon
Just this morning I discovered the Uptime project over on GitHub. The author bills it as "A simple HTTP remote monitoring utility using Node.js and MongoDB". I'm already in love with this tool thanks to its composability and ease of use.
The documentation over at the Uptime project is quite good, so I won't bore you with the details. The basic gist is that you'll want to have a MongoDB server available (OS X users can just brew install mongodb) and Node.js (at least version 0.8). Clone the repo locally and then run node app.js to start the monitor (web UI) and analyzer (check engine).
- Comments (0)
Trip to Italy
2012-10-06 13:21:15 by jdixon
I've just concluded a week in Italy as part of my visit to speak at DevOpsDays Roma. Most people don't know this, but I was an Architecture student at Georgia Tech many years ago. As such, I was exposed to a lot of Greek and Roman history. This made a lasting impression on me; I've always dreamed of visiting Rome and it was a stroke of luck when I heard about the conference and was eventually accepted to speak.
- Comments (0)
Trending your PagerDuty Alerts in Graphite
2012-08-28 12:04:09 by jdixon
We've noticed an increase in alerts recently at $DAYJOB. So naturally we thought it would be helpful to begin tracking Nagios alerts in Graphite. Alas, this will only help us going forward, so I wondered how difficult it would be to retrieve historic data from PagerDuty and import it into Graphite. Turns out it isn't too hard, although we have to work around some of the limitations in PagerDuty's Incidents API.
- Comments (0)
Trending your GitHub Commits in Graphite
2012-07-22 22:45:55 by jdixon
Today I was browsing the list of service hooks that GitHub provides. I almost forgot that there's a simple WebHook service that POSTs commit information during the git post-receive hook to any external URL. This got me thinking that it would be nice to trend commit activity inside my Graphite server. Don't get me wrong... GitHub already provides some really nice visualization for project and committer activity on their site. However, as a data junkie, I'd love to be able to correlate this activity with my own application metrics.
This was a perfect fit for Backstop, the HTTP/JSON-to-Graphite bridge. After a couple hours of futzing around I had a working version. If you haven't used Backstop before, rest assured that getting started is pretty darn easy. In fact, if you're a Heroku customer, it's easy and free. There are just a few commands to get your own Backstop server running on Heroku.
- Comments (0)
Introducing Descartes
2012-07-10 17:51:45 by jdixon
Graphite is renowned for its usefulness and ease for prototyping new charts. It's also known for having a dashboard component that leaves much to be desired. In response the community has seen a rising tide of new dashboard projects aimed at filling this gap. The growing list of third-party Graphite dashboard projects is extensive, but continues to fall short in areas such as self-service, configuration, and collaboration.
Most of this software require users to generate dashboards from JSON or other command-line gymnastics. While this is reasonable for many operations folk, it's an impedance for the engineers and business-oriented users; the same users that we want using this software for making sound decisions. Graph views are static and inflexible for collaboration and historical dialogues. In response to these shortcomings I've started the Descartes project.
- Comments (3)
El Cheapo Network Graph
2012-07-08 12:45:58 by jdixon
Here's an embarrassingly simple script I threw together this morning to track network latency to a handful of remote websites/networks from my home internet. Yes, I understand that these numbers are highly influenced by my proximity to various CDN networks and bear no resemblance to how actual web browsing would perform concurrently. That isn't the point. This is merely to demonstrate a cheap and easy way to get more metrics into Graphite; and at the same time, providing me with some useful reference for when my home internet provider will inevitably have hiccups.
- Comments (1)
Graph Porn and Sharing
2012-07-01 13:43:14 by jdixon
Part of what I see myself doing (by writing blog posts, creating software like Tasseo, etc) is to try and help others learn better ways of communicating our operational knowledge through visualization tools and methodologies. While I've gotten a lot of positive feedback from my Graphite articles, what I haven't seen as much is a two-way sharing of the harvested data made possible through these experiences.
I think there are a couple possible reasons for this: first, we work with "propietary" data that our employers might not want divulged; second, we assume our data is immaterial and not worth sharing. For the former, I think this is a very similar argument that many of us had with employers during the push to open source software. There is much to be gained by sharing our raw data (perhaps without all of the proprietary metadata and labels that make it relevant to our business) and seeing those examples improved upon and returned by our peers.
- Comments (0)
Velocity 2012 Postmortem
2012-06-29 16:23:23 by jdixon
This week I traveled out west for my first Velocity conference as an attendee. I went out two years ago but I was so busy juggling exhibitor duties that I didn't get to enjoy any hallway networking or formal session. This year I went in with plans to catch as many sessions as possible, particularly those skewed towards monitoring, trending and operations workflow. As expected, I skipped quite a few talks but made up for it with a lot of quality time catching up with peers and reviewing new technologies (and philosophies) in the DevOps space.
- Comments (2)
Watching the Carbon Feed
2012-06-01 11:40:25 by jdixon
This is one of my most favorite, and certainly most underappreciated graphs. Its simplicity belies its usefulness. This single chart gives me a holistic view of our metrics feed, writes to Whisper files, as well as general system health. At a glance I can correlate slow updates caused by a spike in Whisper file creations or a backup resulting in a higher PPU value. We use some of its targets with Nagios to monitor for metric feed issues. And it's always the first place I look whenever there's a whiff of Graphite problems.
- Comments (5)
The Story Behind Tasseo
2012-05-07 10:19:32 by jdixon
A little over a week ago I released the Tasseo dashboard. The response I got back was nothing short of astonishing. Tasseo is a Graphite dashboard, one of many to have been released in recent months. That fact alone led me to believe it would fly quietly under the radar. I couldn't have been more wrong; Tasseo (pronounced like Casio) tallied over 200 GitHub watchers in the first weekend, and should pass 300 today.
Tasseo was originally developed as a from-the-ground-up reimplementation of the Pulse dashboard we use at Heroku. Pulse has been a tremendously valuable tool for us; unfortunately, it has some drawbacks that make it a challenge to maintain.
- Comments (9)
A Precautionary Tale for Graphite Users
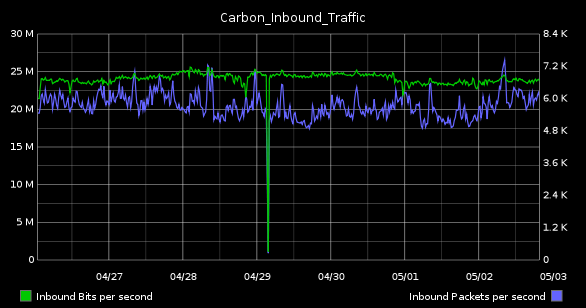
2012-05-02 22:09:36 by jdixon
This morning I was collecting some graphs for one of our weekly status meetings. Asked to find something that represented the state of our Graphite system, I naturally gravitated to my usual standbys, "Carbon_Performance" (top) and "Carbon_Inbound_Bandwidth" (bottom).
| 1-day | 1-week |
|---|---|

|

|

|
|
The SysAdmin in me loves these because they highlight resource utilization on the server. While the former details disk I/O and CPU, the latter tracks inbound bandwidth in terms of bits and packets per-second. Although the network graph seems utterly boring (in as much as we've all used these in one form of another, from vendor-supplied dashboards to Cacti installations), it's this one that is actually the more complicated of the two to configure.
- Comments (6)
Unhelpful Graphite Tip #10 - Time Shifting
2012-04-25 08:44:44 by jdixon
Let's say you want to compare how a particular metric compares to some point in the past. This is a common practice in troubleshooting and capacity planning. What's the best way to achieve this in Graphite?
I might start off by selecting the past four weeks and visually discern the trends from week to week. Here's a graph showing the last month of AMQP activity. We can see that traffic was oscillating quite a bit over the first week and a half before smoothing out and gradually trending downward.

- Comments (10)
Unhelpful Graphite Tip #6 - Filtering by Most Deviant
2012-04-13 09:57:32 by jdixon
I remember one day when I was trying to narrow down an application causing high load on an outlier within a fleet of servers. Nagios wasn't suitable for the task, as it only told me which hosts were currently spiking, not which ones have been spiking for a certain window of time. And it certainly couldn't identify a particular host based on a performance visualization.
My Graphite wizard hat went on and I went to work, narrowing down the list of suspects using wildcards and visually inspecting each host's load profile. Within 5 minutes I found my suspect and basked in my glory.
Naturally my brilliance was short-lived.
- Comments (1)
Unhelpful Graphite Tip #3 - JSON Output
2012-04-11 10:06:13 by jdixon
I love JSON. No really, I fucking love JSON. It might have something to do with its phonetic approximation to my own name. Or it might be my preference for anything that hastens the death of XML. Either way, it's a handy format that's become ubiquitous for data interchange. And fortunately for those of us who prefer our graphs rendered client-side, Graphite supports it as an output format.
- Comments (4)
Unhelpful Graphite Tip #2 - Graph Bookmarklet
2012-04-10 18:58:26 by jdixon
I wish I could say I've been using this little gem for years. Alas, I just learned about it last night courtesy of R. Tyler Croy (@agentdero). This has already been a godsend, in less than one full day of use.
- Comments (3)
Unhelpful Graphite Tip #1 - Frequency of Events
2012-04-10 00:41:02 by jdixon
I'd like to begin sharing more of my knowledge as it pertains to using Graphite in production. Most of these upcoming posts are bound to be of the "check out this cool function" variety, but hopefully you can stitch them together into something useful. Before I proceed, I'd like to thank Chris Davis and the team at Orbitz who started this incredible software project and released it to the open-source community. Without your work I'd be stuck using something... less awesome.
Today's tip comes courtesy of a combined effort by me and Michael Leinartas (@mleinart). I've used this particular combination of functions before to calculate the number of "events" in a series during a particular timeframe. Unfortunately I failed to record this query anywhere (pro-tip: save your best Graphite functions in a document or gist, you'll be glad you did) although I had a vague idea of the functions needed. Michael was kind enough to remind me of the particular order for chaining the functions.
- Comments (6)
PostgreSQL 9.0 createdb Revelations (Updated)
2011-08-27 15:18:16 by jdixon
One of my first projects at Heroku has been to modernize our shared PostgreSQL offering (working with @asenchi). As we get closer to internal testing of our new service, @markimbriaco asked for benchmarks looking for any bottlenecks in PostgreSQL 9.x when creating large quantities of small databases. We've seen instances where Pg 8.3 will start to choke after 2000 databases on the same server and we're hoping that 9.x alleviates this issue.
My initial test was overly simplistic but still revealed some interesting patterns. I started with createdb on the command-line, generating 8000 roles and empty databases, serially. The results were promising, with PostgreSQL 9.0.4 (Ubuntu 10.04) able to scale up without any noticeably increasing latency. Unfortunately, it's not a terribly useful benchmark given the absence of any workload. And yet, I couldn't help but notice a pattern in the scatter plot:

Notice the gap between 500 and 600 ms? I don't have an explanation for this but I suspected that Pg has an internal condition that triggers for actions that take 500ms or longer. Regardless, our primary expectations had been met. Whatever bottleneck 8.3 demonstrated when creating databases on a server with large quantities of existing small databases appears to be fixed in 9.0.
The next test was to run a similar sequence with our new application server. It offers an internal RESTful API using Sinatra and Sequel to provision and manage customer databases on shared servers. The results for this run were even more enlightening. Check out the stratification:
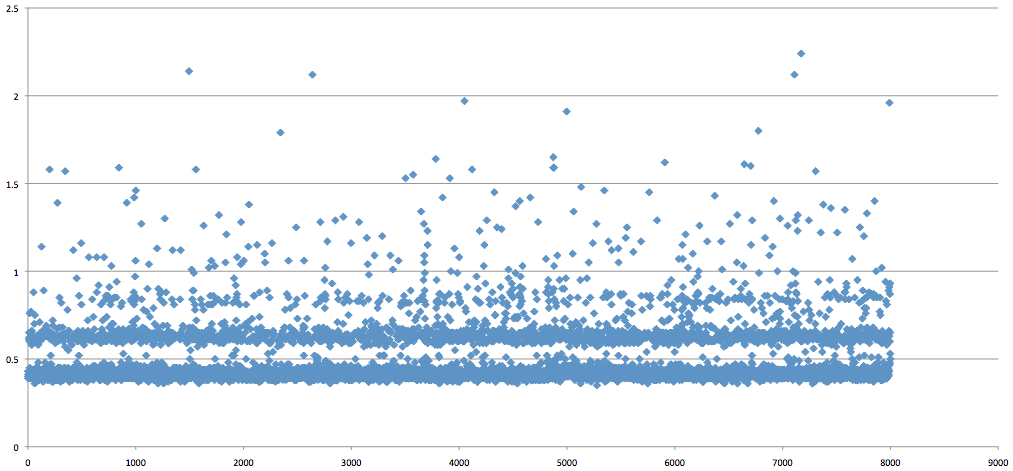
Not only is the initial gap (around 400ms) even more pronounced, but you can see a pattern of latency introduced at 200ms intervals after the initial 400ms delay. I have no explanation for this, but I wanted to publish these results and see if anyone else has a guess as to what might be causing these patterns.
UPDATE: To rule out any distortion caused by GNU time, I ran another test using Ruby's Time class to get a more accurate representation. In the most simple terms, we start the clock with Time.now, connect to the database (no caching), create a role, create the database and stop the clock. Output is logged and then imported into Excel for plotting. I think the results speak for themselves (measured in milliseconds):

- Comments (1)
Giant Robots Are Cool and Shit, But Seriously...
2011-07-15 16:54:34 by jdixon
I'm pleased to see so many people interested in the #monitoringsucks movement/campaign/whatever. My last post seemed to resonate with a lot of you out there. I'm excited to hear discussions surrounding APIs, command-line monitors, monitoring frameworks, etc. But I think a major thrust of my article was missed. It's not just that Nagios can be a pain in the ass, or that we need a modular monitoring system. What I'm trying to emphasize is that monolithic monitoring systems are bad and not suited for the task at hand.
Some very smart systems people (and developers) are trying to solve this problem in the open-source arena. Unfortunately, while they're attempting to diagnose and cure the problems in contemporary monitoring systems, they continue to architect big honking inflexible software projects. When I refer to "the Voltron of monitoring systems" I'm not talking about an enormous fucking automaton of monitoring, alerting and trending components. I mean that each component should exist independently of the others, with a stable data format and communications API. Any single component should be easily replaceable and deprecated. Authors should strive for competition because it makes the inclusive architecture that much stronger.
Realistically I see one of three things happening over the next 12-18 months:
- A community forms around a reasonable set of defined components and begins cranking out useful bits. Over time we have what resembles a useful ecosphere of monitoring tools and users.
- Motivated developers continue to solve the issues affecting monitoring software, but in their own walled garden projects. We benefit from a larger pool of projects to choose from, but they all continue to suffer from NIH syndrome.
- I'm disregarded as a nutcase. Nothing changes and we continue to use the same crappy ubiquitous software.
At this point I think the most likely outcome is a combination of numbers 1 and 2. It's hard for anyone to justify working on a disassociated component when the related components it needs to be useful might never be developed. On the other hand, if someone working on a monolithic project has the foresight to break up the bits into a true Service Oriented Architecture, then it would be feasible for external developers to fork individual units.
- Comments (6)
Monitoring Sucks. Do Something About It.
2011-07-07 23:45:30 by jdixon
For as long as I can remember, systems administrators have bitched about the state of monitoring. Now, depending on who you ask, you might get a half dozen (or more) answers as to what "monitoring" actually means. Monitoring is most commonly used as a casual catch-all term to describe one or more pieces of software that perform host and service monitoring and basic trending (graphs or charts). But in most cases, these complaints are targeted at software responsible for daily fault detection and notifications for IT shops and Web Operations. The usual whipping boy is Nagios, a popular open-source monitoring project that supports a universe of host and service checks, notifications, escalations and more.
Nagios has been the "lesser of all evils" for quite some time. Its cost (free), extensibility (high) and configuration flexibility have helped it achieve significant adoption levels across a variety of industries and range of business sizes, from small one-man web startups to Fortune 500 enterprises. It's been forked multiple times and is recognized by industry analysts as a force to be reckoned with. Regardless, those who use it, do so with a fair amount of hostility. Ask around and you're likely to find more users who stay with Nagios because it's "good enough" than those who actually like it. So why doesn't Nagios have more competition in the open-source marketplace? Largely because writing an entire monitoring system from scratch is an enormous undertaking. Ok, does that mean we should keep improving Nagios (or forking it... again)? Perhaps.
- Comments (10)
Trending with Purpose
2011-03-18 13:52:44 by jdixon
I threw together a presentation on short notice this week for an internal tele-conference about Trending with Purpose. The end result was much better than I might have expected (even given my penchant for procrastinating). Although much of the content is specific to applications currently in use at $DAYJOB, I think there's something to take out of it even if you're not using these tools.
The content is intended for developers who might not (or know how to) use application profiling data to complement their operations' monitoring and trending efforts. Special props to the Orbitz.com developers for open-sourcing their Graphite graphing tool, as well as John Allspaw and the Etsy Engineering team for their work on StatsD, and for generally serving as innovators in the Web Operations industry.
Special note: These slides were thrown together in rapid fashion. Anyone who experiences violent reactions to Gill Sans Italic should not download this slideshow. You have been warned.
The slides are available here.
- Comments (3)
New Year's Resolutions
2010-01-01 22:28:02 by jdixon
I'm not sure how effective it is to post these here, but I'm hopeful that having them in cyberspace will help keep me motivated. I'm hereafter calling these goals rather than resolutions The latter, to me, implies something that you begin immediately. This cold-turkey approach virtually guarantees failure. The moment you trip up, the subconscious immediately considers them a lost cause and reverts to the old behavior. As goals, I think it sets a more optimistic tone and allows me to gradually adapt the preferred conduct.
Without further ado, my personal list of goals for this year (in no particular order)...
- Comments (1)
Business Metrics
2009-09-15 23:58:42 by jdixon
Somewhere between our first corrupt filesystem and an unlikely ascent to CTO, all Systems Administrators are taught to monitor their systems. We're trained to monitor the health of our computers and trend the usage for capacity planning and analytics. A Nagios is deployed; eventually complemented by Cacti; both of which are inevitably supplanted by Something Enterprise (TM). Services are checked, change is managed, and reports are reportified.
Have you asked yourself, what value does this offer my company? Perhaps you've correlated your database connection breakdown time with website load time. Or you noticed that the FULL backups on Sunday coincide with excessive packet loss on your Seattle firewalls. Besides buffing out some of the rough edges on your operational capabilities, how does this data work for you?
- Comments (1)
Noit Grows Hair on Your Chest
2009-08-15 14:09:13 by jdixon
Todd Hoff over at High Scalability takes a look at Reconnoiter. He went through the [currently] arduous task of installing and configuring it manually; setting up checks can be a hairy experience. But the end result seems to justify the initial pain. It's a very exciting (and useful) application that will only get better as the #noit devs continue to hack on it.
As an Ops guy over at OmniTI, I've been fortunate to watch Reconnoiter's incubation process. Theo Schlossnagle is probably one of the smartest guys in this industry and he gets scalability issues. We've batted around ideas about network trend and analysis tools before (e.g. NFDB) so naturally I'm anxious to see where Noit takes us.
- Comments (0)

 RSS 1.0
RSS 1.0