A Precautionary Tale for Graphite Users
2012-05-02 22:09:36 by jdixon
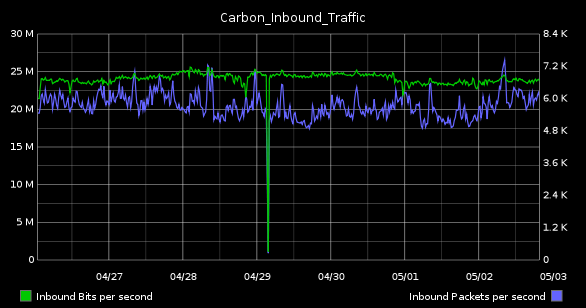
This morning I was collecting some graphs for one of our weekly status meetings. Asked to find something that represented the state of our Graphite system, I naturally gravitated to my usual standbys, "Carbon_Performance" (top) and "Carbon_Inbound_Bandwidth" (bottom).
| 1-day | 1-week |
|---|---|

|

|

|
|
The SysAdmin in me loves these because they highlight resource utilization on the server. While the former details disk I/O and CPU, the latter tracks inbound bandwidth in terms of bits and packets per-second. Although the network graph seems utterly boring (in as much as we've all used these in one form of another, from vendor-supplied dashboards to Cacti installations), it's this one that is actually the more complicated of the two to configure.
At least as of Graphite 0.9.9, there is no magic function to transform counters into their "per-second" equivalents. Hence, we're forced to concoct a scale recipe that transforms to our desired result. In my case, I wanted to present Bits Per Second (bps) as the default unit for this chart. I determined that by taking the nonNegativeDerivative of our SNMP octets counter, multiplying it by eight (to convert to bits) and then dividing by 60 (seconds) would yield the correct number. A quick comparison against the network switch graphs (provided by the vendor, of course) confirmed my calculations that we were indeed receiving approximately 5Mbps of inbound traffic to the Graphite server.
scale(nonNegativeDerivative(snmp.graphite.IF-MIB::ifInOctets.7),0.133333333)
Of course, this was months ago, which all but guarantees I'd forgotten exactly how I'd come to this calculation (or that it was even necessary).
Jump forward to this morning, where I was scratching my head trying to figure out why the 1-week graph (lower right, above) showed traffic levels 5 times greater than the usual 1-day pattern. My first inclination was to check the aggregationMethod for the affected metrics.
# whisper-info.py /data/snmp/graphite/IF-MIB\:\:ifInOctets/7.wsp | grep aggregation aggregationMethod: average
This looked normal (average is the default aggregation function), so my focus went to the data itself. Our retention policies for SNMP data are relatively sane; we like to keep 1-minute resolution for a day, 5-minute resolution for four weeks, and 15-minute resolution for a year.
[snmp] priority = 200 pattern = ^snmp\. retentions = 1m:1d,5m:28d,15m:1y
Using the Graphite web API, I reviewed the raw data for both archives. Everything looked normal.
I went back and looked at the graphs again. This time I attempted to isolate the periods when the graphs looked "good" and when the levels were out of whack. And then it hit me like a ton of bricks. As soon as my view extended beyond the 1-day archive (1m:1d), the numbers skewed by a factor of 5. And if I went beyond the 4-week archive (5m:28d), they jumped up another factor of 3. The totals were off by exactly the same amount as the increase in secondsPerPoint per archive.
# whisper-info.py /data/whisper/snmp/graphite/IF-MIB\:\:ifInOctets/7.wsp | \ > grep -A2 Archive Archive 0 retention: 86400 secondsPerPoint: 60 -- Archive 1 retention: 2419200 secondsPerPoint: 300 -- Archive 2 retention: 31536000 secondsPerPoint: 900
Because I had introduced a time conversion into our scale factor, the data was only valid for the particular archive that I initially verified it against. If we perform any queries that pull from a different archive, the scale calculation is off by the factor of difference in seconds per archive. What was originally designed as a graph that described number of bits per second per one minute interval becomes something more like number of bits per second per five minute interval.
The moral of the story - never attempt to convert time units in your deviance or it will bite you in the ass.
Add a comment:

 RSS 1.0
RSS 1.0
Comments
at 2012-05-02 22:54:33, Corry wrote in to say...
There are ways to resolve this though (and I should really push this patch upstream): https://github.com/tabletcorry/graphite/commits/step-derive
at 2012-05-02 22:57:32, Jason Dixon wrote in to say...
@Corry - Absolutely. As I mentioned, this is afaik simply missing from 0.9.9. I think that there's something similar already in 0.9.10 or almost certainly the metacarbon branch.
at 2012-09-11 04:28:30, Mike Pennington wrote in to say...
FYI Jason, it seems that you're storing your interface data as the SNMP ifIndex value. Keep in mind that technically, ifIndex values are arbitrary and determined by the platform at boot time. It's better to resolve those index values to a real interface name before storing in carbon; that way your data can't get hosed if the device reboots.
at 2012-10-30 11:41:24, NB wrote in to say...
So for late visitors to this issue, scaleToSeconds() was added to 0.9.10 for cases like this.
at 2014-01-06 16:24:44, BD wrote in to say...
OK, so how to solve this problem at all, i mean, what is the full solution? I've got exact same issue as you, and test a bunch of functions without success.
I got snmp counters and i want to store them in retentions like: 60s:1d, 300s:1w... etc. but my graphs are broken.. any help is appreciated.
Thanks in advance.
at 2015-12-09 17:03:36, turner wrote in to say...
@NB as far as i can tell, scaleToSeconds has the exact same issues as scale. specifically, it seems to use the minimum rollup interval to calculate a fixed scale regardless of the actual resolution of the underlying data. for example, our data is kept in the following rollups: 10s, 1m, 5m, 15m, 1h, 6h. when i apply scaleToSeconds(1) to a graph, it has the exact same behavior as applying scale(0.1)