Benchmarking Carbon and Whisper 0.9.15 on AWS
2016-08-25 15:40:17 by jdixon
This is just a quick post to share some recent benchmarking results for a single Graphite 0.9.15 server. The host is a single EBS-optimized EC2 i2.4xlarge instance with a 400 GiB EBS Provisioned IOPS SSD (io1) with a requested 20k Max IOPS.
I'm not going to dive in too deep with the results, but I'll point out that with the following configuration we were able to increase batch writes effectively, resulting in a peak 38 points per update (pointsPerUpdate, averaged across all cache processes). This means that on average, caches were able to flush 38 datapoints from memory to disk with every write request.
The carbon configuration below is pretty reasonable, with six (6) relays and eight (8) caches behind a single HAProxy listener. The MAX_CACHE_SIZE has been tuned over the course of a few tests to find a comfortable, finite limit that would accommodate the intended volume of 60k metrics/second. MAX_UPDATES_PER_SECOND was set intentionally low in order to trigger the aforementioned high "points per update multiplier".
The retention policy for our benchmark metrics (seen below, storage-schemas.conf) was selected to resemble a reasonable real-life, production environment. You could absolutely get more volume or consume fewer resources by removing any of the rollup archives or lowering the precision for the [haggar] metrics. I also expect that swapping in a more performant relay alternative would result in significant efficiencies.
Metric traffic was generated using Haggar, a tool which aims to emulate a fleet of servers running the collectd agent, emitting metrics to Carbon.
I'm happy to answer any questions in the comments below regarding this benchmark or other possible benchmarks. Note that I intend to run the same test against Graphite master very soon and will post a follow-up when that is complete.
# carbon.conf
[relay]
USER = carbon
LOG_LISTENER_CONNECTIONS = False
RELAY_METHOD = consistent-hashing
REPLICATION_FACTOR = 1
MAX_DATAPOINTS_PER_MESSAGE = 500
MAX_QUEUE_SIZE = 10000
USE_FLOW_CONTROL = True
DESTINATIONS = 127.0.0.1:2104:1, 127.0.0.1:2204:2, 127.0.0.1:2304:3,
127.0.0.1:2404:4, 127.0.0.1:2504:5, 127.0.0.1:2604:6,
127.0.0.1:2704:7, 127.0.0.1:2804:8
[relay:1]
LINE_RECEIVER_PORT = 2113
PICKLE_RECEIVER_PORT = 2114
[relay:2]
LINE_RECEIVER_PORT = 2213
PICKLE_RECEIVER_PORT = 2214
[relay:3]
LINE_RECEIVER_PORT = 2313
PICKLE_RECEIVER_PORT = 2314
[relay:4]
LINE_RECEIVER_PORT = 2413
PICKLE_RECEIVER_PORT = 2414
[relay:5]
LINE_RECEIVER_PORT = 2513
PICKLE_RECEIVER_PORT = 2514
[relay:6]
LINE_RECEIVER_PORT = 2613
PICKLE_RECEIVER_PORT = 2614
[cache]
USER = carbon
CACHE_WRITE_STRATEGY = sorted
MAX_CACHE_SIZE = 3000000
USE_FLOW_CONTROL = True
WHISPER_FALLOCATE_CREATE = True
MAX_CREATES_PER_MINUTE = 12000
MAX_UPDATES_PER_SECOND = 200
USE_INSECURE_UNPICKLER = False
LOG_CACHE_HITS = False
LOG_CACHE_QUEUE_SORTS = False
LOG_LISTENER_CONNECTIONS = False
LOG_UPDATES = False
ENABLE_LOGROTATION = False
WHISPER_AUTOFLUSH = False
[cache:1]
LINE_RECEIVER_PORT = 2103
PICKLE_RECEIVER_PORT = 2104
CACHE_QUERY_PORT = 7102
[cache:2]
LINE_RECEIVER_PORT = 2203
PICKLE_RECEIVER_PORT = 2204
CACHE_QUERY_PORT = 7202
[cache:3]
LINE_RECEIVER_PORT = 2303
PICKLE_RECEIVER_PORT = 2304
CACHE_QUERY_PORT = 7302
[cache:4]
LINE_RECEIVER_PORT = 2403
PICKLE_RECEIVER_PORT = 2404
CACHE_QUERY_PORT = 7402
[cache:5]
LINE_RECEIVER_PORT = 2503
PICKLE_RECEIVER_PORT = 2504
CACHE_QUERY_PORT = 7502
[cache:6]
LINE_RECEIVER_PORT = 2603
PICKLE_RECEIVER_PORT = 2604
CACHE_QUERY_PORT = 7602
[cache:7]
LINE_RECEIVER_PORT = 2703
PICKLE_RECEIVER_PORT = 2704
CACHE_QUERY_PORT = 7702
[cache:8]
LINE_RECEIVER_PORT = 2803
PICKLE_RECEIVER_PORT = 2804
CACHE_QUERY_PORT = 7802
# storage-schemas.conf [collectd] pattern = ^collectd\. retentions = 10s:1w, 60s:1y [haggar] pattern = ^haggar\. retentions = 10s:1d, 60s:1w, 1h:1y [default] pattern = .* retentions = 60s:1y
# haproxy.cfg
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
user haproxy
group haproxy
daemon
maxconn 8192
pidfile /var/run/haproxy.pid
defaults
balance roundrobin
log global
mode tcp
retries 3
option redispatch
contimeout 5000
clitimeout 50000
srvtimeout 50000
# plaintext listener
listen carbon_relay_2003 0.0.0.0:2003
server carbon_relay_2113 127.0.0.1:2113 check maxconn 1024
server carbon_relay_2213 127.0.0.1:2213 check maxconn 1024
server carbon_relay_2313 127.0.0.1:2313 check maxconn 1024
server carbon_relay_2413 127.0.0.1:2413 check maxconn 1024
server carbon_relay_2513 127.0.0.1:2513 check maxconn 1024
server carbon_relay_2613 127.0.0.1:2613 check maxconn 1024
# pickle listener
listen carbon_relay_2004 0.0.0.0:2004
server carbon_relay_2114 127.0.0.1:2114 check maxconn 1024
server carbon_relay_2214 127.0.0.1:2214 check maxconn 1024
server carbon_relay_2314 127.0.0.1:2314 check maxconn 1024
server carbon_relay_2414 127.0.0.1:2414 check maxconn 1024
server carbon_relay_2514 127.0.0.1:2514 check maxconn 1024
server carbon_relay_2614 127.0.0.1:2614 check maxconn 1024
$ GOPATH=~/gocode ./gocode/bin/haggar -agents=300 \
-metrics=2000 \
-carbon="x.x.x.x:2003"
 Fig 1: Grafana dashboard for Carbon & Whisper
Fig 1: Grafana dashboard for Carbon & Whisper
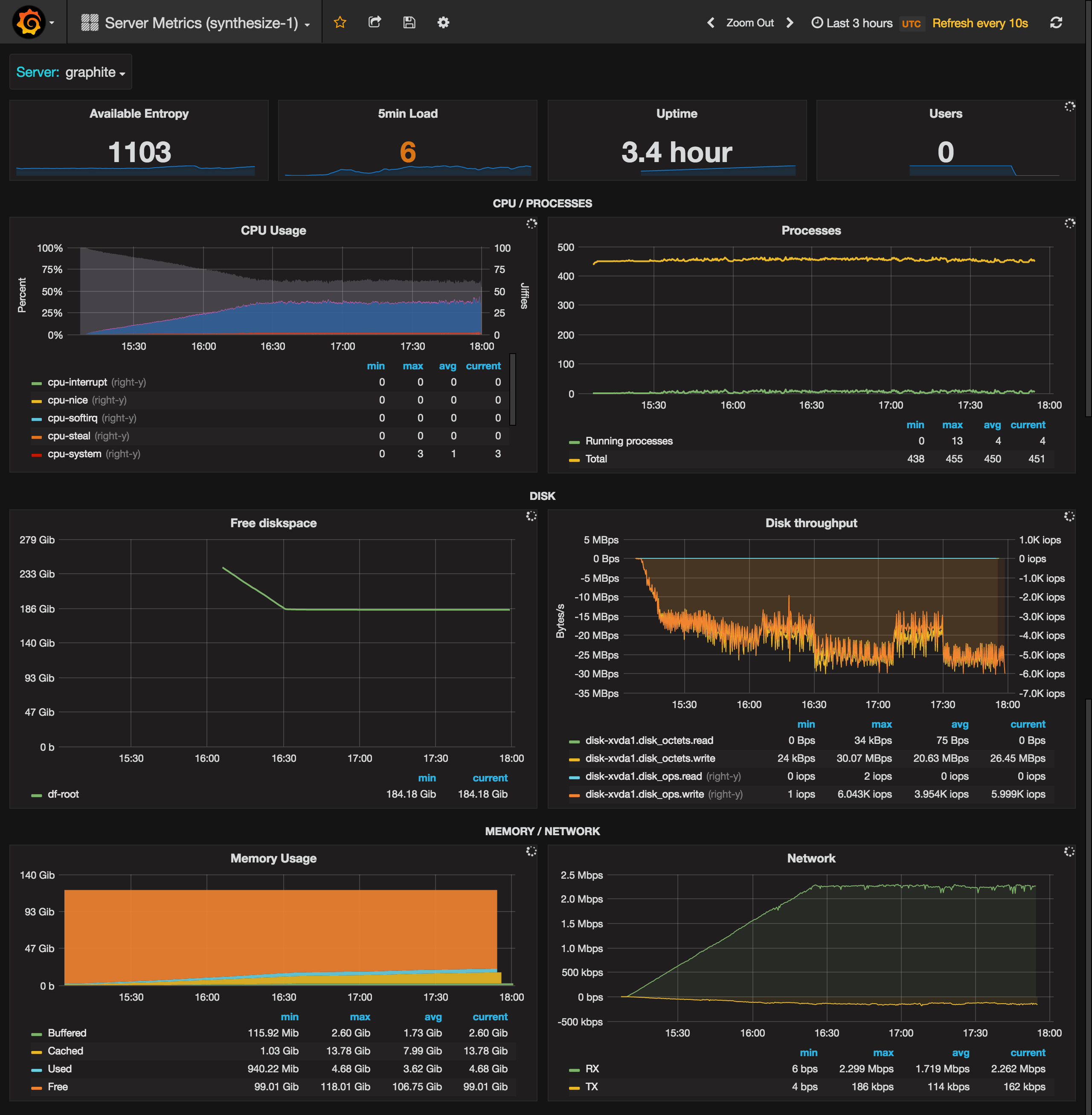 Fig 2: Grafana dashboard for collectd
Fig 2: Grafana dashboard for collectd
 Fig 3: top output for Carbon
Fig 3: top output for Carbon
Add a comment:

 RSS 1.0
RSS 1.0
Comments
at 2016-08-26 01:31:13, Dieter_be wrote in to say...
What happens if you push it further? does it saturate any resource? What's the bottleneck?
at 2016-08-26 02:17:40, Ctrlok wrote in to say...
Hi. I already did benchmarks for carbon and want to recommend go carbon — it can receive and save from cache up to 200k unique metrics per second on m4.xlarge instance 500 go ebs without provisioned iops.
at 2016-08-26 15:11:42, Jason Dixon wrote in to say...
@dieter_be The general bottleneck is in IO but this can manifest itself as excessive memory (which can in turn result in dropped datapoints) or cpu (due to sorting datapoints in queues) but this is all highly dependent on how the server is configured. I think we all recognize that Whisper's major resource is IO; fortunately you can squeeze a lot out of any single system with the right configuration.
at 2016-08-26 15:13:06, Jason Dixon wrote in to say...
@Ctrlok Good to know. I'm planning to run the tests with alternate relays to see just how good the results can be.
at 2016-08-28 09:06:56, FRLinux wrote in to say...
Hey Jason,
That is quite interesting. My record so far was 6M metrics/mn on bare metal (few SSDs on RAID6), I had about 20k IOPs also. There was some queuing happening though but memory polling hid that nicely.
I am however interested to see where AWS brings us. Jason, can you expand on how you calculated this one? MAX_CACHE_SIZE = 3000000
at 2016-08-30 09:14:00, Jason Dixon wrote in to say...
@FRLinux Yes, the `MAX_CACHE_SIZE` represents how many datapoints a cache instance should hold in memory. I increased this to fit the required number of datapoints in memory (as measured by `carbon.agents.<instance>.cache.size`). If and when I ever calculated it too low, I would get "MetricCache is full" errors in the respective console.log.
at 2016-08-30 18:24:34, FRLinux wrote in to say...
Nice one, thanks for that!
at 2016-08-30 20:09:33, Steven Acreman wrote in to say...
Hi Jason, I've also been doing a fair bit of work in this area. It would be great to include some solid benchmarks for Graphite in this spreadsheet:
https://docs.google.com/spreadsheets/d/1sMQe9oOKhMhIVw9WmuCEWdPtAoccJ4a-IuZv4fXDHxM/edit#gid=0
There seem to be so many options to tune Graphite I've split the columns into what you can expect to get out of the box by following the documents and what you can get when you swap out various components or run under a JIT'ed python etc.
Also, I've been using Haggar to benchmark Dalmatiner again on a standardise size server. I went with 16 cpu's, 60GB ram and a locally attached SSD. On GCE that's an n1-standard-16 and on AWS the closest would be hi1.4xlarge which has locally attached disks. Benchmarking on EBS makes it hard to recreate outside of Amazon's cloud and remote storage adds another dimension of latency that's hard to factor out.
Here's my Haggar setup which I used. Would be good to try to standardise that too. I'm happy to change to whatever settings you're using or it would be good to get some results with similar setup to these:
https://gist.github.com/sacreman/b77eb561270e19ca973dd5055270fb28
Thanks!
at 2016-09-11 22:57:37, Jason Dixon wrote in to say...
@Steven I've been running recent Graphite master benchmarks on a Packet type3 instance (https://www.packet.net/bare-metal/) which gives us a ton of headroom. Recent tests have hit 300k/sec and I'm still seeing how hard we can push it before it falls over.
The setup used 8 relays with 16 caches, a MAX_CACHE_SIZE = 4000000, and MAX_UPDATES_PER_SECOND = 20000, yielding 23 datapoints per batch update.
Note that it would be great if you could elaborate on your "it doesn't scale" criteria.
at 2016-09-12 10:40:53, Steven wrote in to say...
Hi, that sounds like a good improvement in performance on 60k/s from the original blog post. Never heard of Packet before but it fulfils the criteria of being a low cost option that anyone can setup for less than $100 to test for a few hours unlike some of the other benchmarks we've been given using fancy hardware.
For the spreadsheet we'd like to keep the best quality benchmark. For example if the best quality benchmark we can find was a good one at 30k we don't just scrap that and go with 200k word of mouth option.
This blog for 60k/sec is good and is currently linked as green in the spreadsheet. we could change it to 300k/sec but we would have to lower the quality to red.
If there was a source that demonstrated clearly how to fully reproduce the result by someone attempting it with no guesswork I'd link at 300k/sec in green. The vagueness about what code is actually running (latest master is a very changeable thing) as well as mentioning that additional tuning is even still under way leads me to believe that an attempt by anyone else to reproduce the 300k/sec using this blog plus the comment above would be a frustrating exercise.
My concerns around the scaling are related to complexity and design. You can shard data infinitely across boxes using pretty much any technology. There are a couple of issues with Graphite that many tout as benefits, but actually become weaknesses.
1. Graphite is made up of many interchangeable parts. Just like my car. I could even swap out the engine for a V8 engine with enough time and effort. Is it still the same car? I fully understand why you may want to swap things out but there has to be a baseline to work from.
2. The manual sharding is a killer. The amount of time and effort up front with planning, and then having to offload everything onto a human to set it up right is a massive negative. 'It' when talking about Graphite itself does not scale. The very, very, very experienced Graphite user spends a lot of time doing the manual scaling.
I'm sure you'll disagree with both points. There are reasons for being composable and there are clearly ways, with considerable effort, to setup Graphite with a high volume of metrics. What happens in reality is that I just always see single node silo's of Graphite everywhere. Teams will setup a single box per team and just have data all over the place. In comparison, and I know this isn't time series, it's pretty common for me to encounter 50 node+ Elasticsearch clusters being run by a single admin and setup in a few hours.
So I'm standing by my "it doesnt scale' review for a while longer. I think things could improve massively for Graphite if some work was done to form a cohesive standardised stack of the best components which was well documented and linked from the front page and benchmarked sensibly.
However, none of that is going to get around that fact that clustering wasn't baked in up front. Perhaps when the new Cassandra backend work is complete and the Graphite component simply becomes an API we could technically say it scales. But is it even still Graphite then? Any database could add that. Will that be the defacto documented stack and what everyone works on and improves over time?
Anyway, until then it's all a bit of a mess and we can only really judge things off of what's available right now and put forward as the current project.
Very similar issue with the data model. The current model isn't great and work is being done to add tags. Nothing currently exists so we can't take those into account either. When they do exist will that considerably change the API to the point where it isn't really Graphite any more? I went to a festival once and remember seeing a band called Atomic Kitten where literally every single band member had left and was replaced by someone new, singing new songs. Perhaps that is the nature of some open source
at 2016-09-12 12:03:22, Jason Dixon wrote in to say...
@Steven The comments section on my blog is a really bad place for a drawn-out conversation around scaling Graphite but I'll do my best to address your points.
I'm happy to add a post detailing the exact configuration and commit(s) handling 300k metric/sec. I'll work on this today.
Many interchangeable parts? The official stack is graphite-web, carbon, and whisper. It supports pluggable storage backends. I'm not sure how you're seeing this as a negative but good luck with that spin.
Manual sharding is a common technique across numerous client-server stacks. There's nothing magical or unintuitive about it that a mid-level administrator shouldn't have already learned. You keep referring to it as a "killer" fault, which is completely disingenuous. Your bias is clearly leaking through here.
The notion of "automatic sharding" is a fairly recent concept associated with NoSQL type databases. In theory this is a great idea that almost never pans out in real-world use, and they often require a high level of domain specific knowledge to maintain and (gasp) scale.
That you "see single node silo's of Graphite everywhere" is a tribute to its popularity. I've seen countless installations of Graphite scaled both vertically and horizontally. Again, it sounds as if you're trying (poorly) to imply that Graphite can't scale. This simply isn't true and destroys your credibility as an impartial technical leader.
Anyways, it's pretty clear that you're excited about your own project and I'm happy for you. I'm really supportive of your TSDB spreadsheet to help folks make an educated decision, but there's no need to spread misinformation or negative subjective implications that are easily contradicted. Every TSDB has its own set of compromises and it's vital that we present this information as objectively as possible.
at 2016-09-12 12:35:20, Steven wrote in to say...
Yes, I was also getting a bit worried about a flame war over opinions on what constitutes scalability, I doubt either us would benefit from trying to convince the other and I think people will see both sides as I do and pick the one they mostly agree with. There are a very long list of databases that scale nowadays simply by adding nodes and typing a command.
For Graphite we actually have two columns. The column with the official documented setup which hopefully I can update to a higher figure later with a better blog link (and ideally that would be linked from the project docs at some stage, or pasted in).
Then there's the second column which we thought could link to a mega setup where everything had been replaced and it was more like a rally car than something you'd pick up off the shelf. If you see any links to reproducible benchmarks above the current number for that one I'd be happy to keep that one updated as the 'fastest you could possibly achieve' on a single node.
I remember a blog by Baron a while ago where you accused him of the same commercial bias. I honestly couldn't see how he could financially gain from promoting or disparaging Graphite, but at the time you were reasonably neutral, so I thought nothing of it. Unfortunately, now you're actually working for a company who's trying to sell things related to Graphite and I have literally zero to gain either way. I'd put that back to you when talking about credibility.
at 2016-09-12 12:45:51, Jason Dixon wrote in to say...
@Steven I stand by my assertion that you're clearly biased (as was Baron) and I think anyone who reads that document and is aware of your association with Dalmatiner can make the same deduction. I'm concerned that you can't see how this misinformation could be used to further your own gains. You're welcome to question my credibility but my only mission here is to provide objective information to help the Graphite community use the project effectively. I'm not disparaging anyone else's project with false claims or misinformation.
at 2016-09-12 16:41:24, Heinz N. Gies wrote in to say...
Good greif you two get a room!
Author of DalmatinerDB here, would like to clarify something. Steven has really an affiliation with DalmatinerDB he (and his company) are using it and have contributed some code. They are obviously very happy with it but neither do they hold any rights nor profit from it other then as users.
Bias is such a quick and easy accusation to throw around. Of cause Steven is biased but only as biased as a happy user is. And just the same Jason is biased given on his experience. We all are formed by our experiences (good and bad) in what we like and don't like. And I am biased based on mine. The experience of two people are not the same so usually their opinions differ. But Steven is certainly not financially motivated. God help me if I ever let him, or anyone else for that matter, call the shots on my projects.
Things that are measurable like throughput, or performance are rather easy to get a baseline on but scaleability is a bit of a less objective measurement. What some one with tons of experience (and I think it's safe to assume Jason can be seen as that) feels about a product is a very different of what someone starting from scratch does. In that sense of cause graphite is scalable, but perhaps not as easy as many people would like - given the repeated complains that it isn't (as false as they might be) kind of indicates that.
at 2016-09-12 22:37:32, Jason Dixon wrote in to say...
@Heinz Frankly I don't care if he has a bias or not, and I don't care which projects he uses and/or supports. I just ask that folks refrain from spreading misinformation or conjecture as it pertains to other projects.
at 2017-02-16 12:36:12, Luiz Gustavo Tonello wrote in to say...
Hi @Jason,
Only today I've had a chance to see this post and it help me a lot.
My bottleneck is I/O, obviously. I'm using 2 basic servers in OVH, with SSDs and I'm suffering with 100% of I/O.
OK, the performance of these SSDs are not the best one.
I was doing ~32k of updateOperations for 4 pointsPerUpdates and an infinite MAX_CACHE_SIZE.
Only the action to change my MAX_UPDATES_PER_SECOND from 600 to 100 (for each carbon-cache) decrease my I/O percentage to ~75%.
And now I'm doing 6k of updateOperations for ~25 pointsPerUpdates.
I'm receiving a total of ~400k metrics and my environment are stable.
Thank you for share your knowledge with us.
Regards,